11-1. 앙상블
1. 앙상블 러닝이란?
1.1 Ensemble learning의 배경
- Ensemble Algorithm: 단일 알고리즘보다 적당한 알고리즘을 여러 개 혼합하여 성능의 개선을 기대하는 방법
Relative Performance Examples: 5 Algorithms on 6 Datasets(John Elder, Elder Research & Stephen Lee, U. Idaho, 1997)
Ensemble learning의 정의
- 여러 개의 결정 트리(Decision Tree)를 결합하여 하나의 결정 트리보다 더 좋은 성능을 내는 머신러닝 기법이다.
- 앙상블 학습의 핵심은 여러 개의 여러 개의 약 분류기(Weak Classifier)를 결합하여 강 분류기(Strong Classifier)를 만드는 과정이다.
- 여러 개의 단일 모델들의 평균치를 내거나, 투퓨를 해서 다수결에 의한 결정을 하는 등 여러 모델들의 집단 지성을 활용하여 더 나은 결과를 도출해 내는 것에 주목적이 있다.
장점

- 성능을 분산시키기 때문에 과적합(Overfitting)을 감소하는 효과가 있다.
- 개별 모델 성능이 잘 안나올 때 앙상블 학습을 이용하면 성능이 향상될 수 있다.
1.2 Ensemble Learning의 기법
1. Bagging - Boostrap Aggregation(샘플을 다양하게 생성하는 방법)
2. Voting(투표) - 투표를 통해 결과를 도출하는 방법
3. Boosting - 이전 오차를 보완하며 가중치를 부여하는 방법
4. Stacking - 여러 모델을 기반으로 meta 모델
1.3 다수결 투표 방법
배깅(Bagging)
Bootstrap Aggregation의 약자로, 훈련세트(Training Set)에서 중복을 허용하여 샘플링하는 방식 배깅(Bagging)이라고 한다.

페이스팅(Pasting)
훈련세트에서 중복을 허용하지 않고 샘플링하는 방식이다.
보팅(Voting)
- 투표를 통해 결정하는 방식으로 Bagging과 같은 투표방식을 사용하지만, 큰 차이점이 존재한다.
1) Voting은 다른 알고리즘 model을 조합해서 사용한다.
2) Bagging은 같은 알고리즘 내에서 다른 Sample을 조합해서 사용한다.
- Voting은 서로 다른 알고리즘이 도출해 낸 결과물에 대하여 최종 투표하는 방식이다.
- Hard Vote와 Soft Vote로 나뉜다.
- Hard Vote는 결과물에 대한 최종 값을 투표해서 결정하고, Soft Vote는 최종 결과물이 나올 확률 값이 다 더해서 최종 결과물에 대한 각각의 확률을 구한 뒤 최종값을 도출한다.
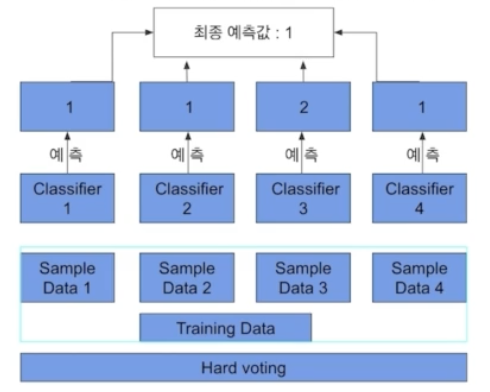
Hard Voting
다수결의 원칙과 비슷하다.
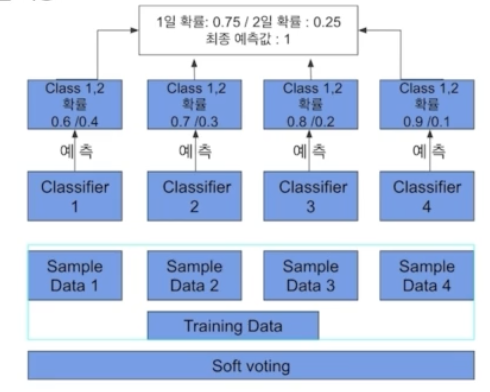
Soft Voting
분류기들의 레이블 값 결정 확률을 모두 더하고 이를 평균해서 이들 중 확률이 가장 높은 레이블 값을 최종 보팅 결괏값으로 선정한다.
일반적으로 소프트 보팅을 적용한다.
Bagging vs Voting

Boosting
여러 개의 분류기가 순차적으로 학습을 수행하는 방식을 의미한다.

Bagging에 비해 성능이 잘 나오지만, Sequential 하게 학습해야 하기 때문에 Bagging보다 속도가 느리고 Overfitting이 발생할 확률이 높다.
Bagging vs Boosting

Stacking
여러 모델들을 활용해 각각의 예측 결과를 도출한 뒤 그 예측 결과를 결합해 최종 예측 결과를 만들어 내는 것이다.

- Support Vector machine, Random Forest 등을 "Base Learner"라고 하고, 이것들의 예측값을 이용해 Output을 예측하는 것을 "Meta 모델"이라고 한다.
- 성능이 극적으로 향상하지만, Overfitting의 위험이 있다.
- Meta 학습이 하기 때문에, 성능이 우수하다. → kaggle 같은 곳에서 마지막에 성능을 향상할 때 많이 사용하는 방법이다.
2. Tree Algorithms
2-1. Decision Tree
Impurity
- 해당 노드 안에서 섞여 있는 정도가 높을수록 복잡성이 높고, 덜 섞여 있을수록 복잡성이 낮다.
- Impurity를 측정하는 측도에는 다양한 종류가 있는데, Entropy와 Gini에 대해서만 알아보도록 한다.

Gini Index
- 불순도를 측정하는 지표로서, 데이터의 통계적 분산정도를 정량화하여 표현한 값이다.

Graphviz
- Tree를 시각화하는 방법이다.

2.2 Gradient Boosting
Pseudo Code

2.3 XGboost
1) XGboost는 Gradient Boosting에 Regularization term을 추가한 알고리즘이다.
2) 다양한 Loss Function을 지원해 task에 따른 유연한 튜닝이 가능하다는 장점이 있다.

2.4 LightGBM
1) Level-wise growth(XGBoost)의 경우 트리의 깊이를 줄이고 균형 있게 만들기 위해서 root노드와 가까운 노드를 우선적으로 순화하여 수평성장하는 방법이다.
2) leaft-wise growth(LightGBM)의 경우 loss 변화가 가장 큰 노드에서 분할하여 성장하는 수직 성장방식이다.
3) GOSS: Gradient-based One-Side Sampling
- 기울기가 큰 데이터 개체 정보 획득에 있어 더욱 큰 역할을 한다는 아이디어에 입각해 만들어진 테크닉, 작은 기울기를 갖는 데이터 개체들은 일정 확률에 의해 랜덤 하게 제거된다.
4) EFB: EXclusive Feature Bundling
- 변수 개수를 줄이기 위해 상호배타적인 변수들을 묶는 기법이다.
5) 일종의 차원 축소 기법이지만, 어떤 feature을 골라야 하는지 결정하는 것이 문제가 된다.
2.5 Catboost
1) 순서형 원칙(Ordered Principle)을 제시한다.
- Target leakage를 피하는 표준 그래디언트 부스팅 알고리즘을 수행하고 범주형 Feature를 처리하는 새로운 알고리즘이다.
2) Random Permutation
- 데이터를 셔플링하여 뽑아낸다.
3) 범주형 feature 처리하는 방법
- Ordered Target Encoding
- Categorical Feature Combinations
- One-Hot Encoding
4) Optimized Parameter Tuning
5) Catboost의 기본적인 하이퍼 파라미터의 디폴트가 잘 설정되어 있고, 최적화가 잘 되어 있기 때문에, 파라미터 튜닝을 크게 신경 쓰지 않아도 된다.
3. TabNet
- Tabular Data를 위한 딥러닝 모델이다.
- TabNet: Attentive Interpretable Tabular Learning, Sercan Ö. Arik, Tomas Pfister 논문을 통해 공개
Key point
1) TabNet은 전처리 과정이 필요하지 않다.
2) 정형 데이터에 대해서는 기존의 Decision tree-based gradient boosting(xgboost, lgbm, catboost)와 같은 모델에 비해 신경망 모델은 아직 성능이 안정적이지 못하다. 두 구조의 장점을 모두 갖는 신경망 모델이다.
3) Feature selection, interpretability(local, global)가 가능한 신경망 모델, 설명가능한 모델이다.
4) feature 값을 예측하는 Unsupervised pretrain 단계를 적용하여 상당한 성능 향상을 보여준다.
- TabNet은 순차적인 어텐션(Sequential Attention)을 사용하여 각 의사 결정 단계에서 추론할 특징을 선택하여 학습 능력이 가장 두드러진 특징을 사용한다.
* 기존의 머신러닝 방법에서는 이러한 특징 선택과 모델 학습의 과정이 나누어져 있지만, TabNet에서는 한 번에 가능
* 특징 선택이 이루어지므로 어떠한 특징이 중요한지 설명이 가능하다.
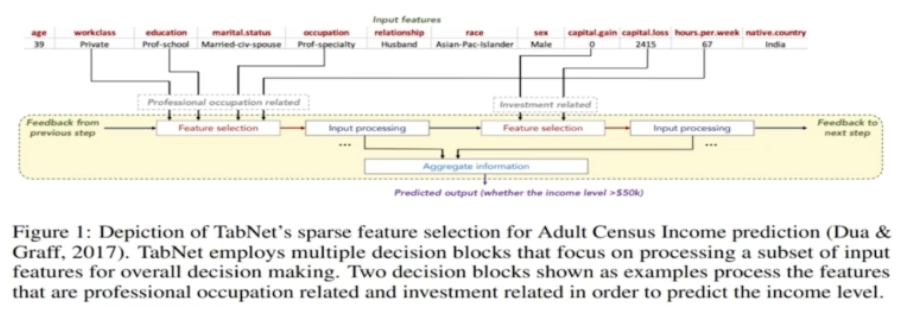



- TabNet은 딥러닝 모델 치고, 조절해야 하는 파라미터가 많다는 단점을 가지고 있다. → 파라미터 선택에 시간이 많이 소요된다.
© NAVER Connect Foundation. All Rights Reserved
'취업준비 > 인공지능' 카테고리의 다른 글
| [AI Tech] 2주차 12차시 프로젝트 4 (0) | 2024.01.27 |
|---|---|
| [AI Tech] 2주차 11-2차시 Quiz 5 (1) | 2024.01.27 |
| [AI Tech] 2주차 10-2차시 하이퍼 파라미터 튜닝 연습 (0) | 2024.01.24 |
| [AI Tech] 2주차 10-1차시 하이퍼 파라미터 튜닝 (0) | 2024.01.24 |
| [AI Tech] 2주차 9-3차시 Quiz 4 (2) | 2024.01.24 |
