27-2. Sequential Models - Transformer
1. Sequential Model
무엇이 sequential modeling 다루기 어렵게 만드는가?

순차적으로 데이터가 들어갈 경우 데이터가 잘리거나, 데이터 중간에 없어지거나 데이터가 섞일수도 있다.
(우리가 문장을 완벽하게 만들어 말하지 않는 것과 동일하다고 생각하면 쉽다)
2. Transformer

Transformer is the first sequence transduction model based entirely on attention.
From a bird's-eye view, this is what the Transformer does for machine translation tasks.

e.g. GPT-3 기반의 DALL-E(이미지 생성 AI)
If we glide down a little bit, this is what the Transformer does.

입력은 세 개의 단어로 되어 있고 출력은 4개의 단어로 되어 있다.
입출력의 도메인이 다를 수 있다.
원래 RNN의 경우 3개의 단어가 들어가면 3번 돌게 되는 데,
이번 것의 경우 한 번에 N(가변적인)개의 단어를 한 번에 처리할 수 있는 구조이다.
1) 인코더에서의 N개의 단어 처리하기

The self-attention in both encoder and decoder is the cornerstone of Transformer.

첫 번째, 각 단어를 임베딩되어있는 벡터로 표현한다.

그 다음, Transformer는 Self-Attention을 이용하여 각 단어들을 feature vector로 인코딩한다.
다만, Self-Attention은 의존성이 있다. Feed Forward에는 의존성이 없다.

예를 들어, 다음 두 단어를 인코딩한다고 하자: Thinking과 Machines
Self-Attention at a high level: The animal didn't cross the street because it was too tired.
여기서 it은 animal을 설명한다고 볼 수 있다.(다른 단어와의 관계성을 보게 된다)


Querey, Key, Value 벡터들은 단어, 즉 입력 하나가 주어졌을 때 세 개의 벡터를 만들게 된다.

Key Vector를 구하기

Score Vector가 나오면 normalize를 한다.



Q, K 그리고 V를 X로부터 구하기 위해 계산한다.
2) Encoder와 Decoder 사이에 어떤 정보를 주고 받는지 알아야 한다.
조금 더 유연한 모델을 표현할 수 있다.

만약 8개의 head가 사용된다면, 서로 다른 8개의 인코딩 벡터를 얻는다.

We simply pass them through additional(learnable) linear map.
여기서 단순히 학습할 수 있는 추가적인 선형 map을 통과시킬 수 있다.


4-dimensional encoding

512-dimensional encoding

최근에는(2020년) positional encoding이 바뀌었다.



3) Decoder가 어떻게 생성하는지 알아야 한다.
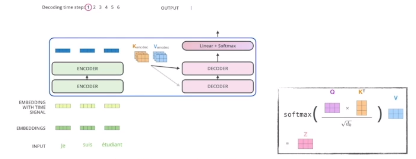
The output sequence is generated in an autoregressive manner.

In the decoder, the self-attention layer is only allowed to attend to earlier positions in the output sequence which is done by masking future positions before the softmax step.
뒤에 있는 단어들은 dependent하지 않게 만드는 방법 중 하나이다.

The final layer converts the stack of decoder outputs to the distribution over words.
3. Vision Transformer

원래는 번역 문제에만 활용되었지만, attention이라는 구조를 sequence를 바꾸는 것 뿐만 아니라 이미지 도메인에도 많이 활용하고 있다.
4. DALL-E

결국은 Attention이라는 것은 자연어 처리 뿐만 아니라 이미지 등 다양한 분야에도 많이 활용되고 있다.
ⓒ NAVER Connect Foundation. All Rights Reserved.
'취업준비 > 인공지능' 카테고리의 다른 글
| [AI Tech] 6주차 27-4차시 Quiz 11 (0) | 2024.02.23 |
|---|---|
| [AI Tech] 6주차 27-3차시 RNN 연습 (0) | 2024.02.23 |
| [AI Tech] 6주차 27-1차시 Sequential Models - RNN (0) | 2024.02.21 |
| [AI Tech] 6주차 26-2차시 Quiz 10 (2) | 2024.02.20 |
| [AI Tech] 6주차 26-1차시 Computer Vision Applications (2) | 2024.02.20 |
