25-2. Modern CNN - 1 x 1 convolution의 중요성
Modern이라는 말에는 어패가 있는 것 같다. → 기본적인 CNN보다 Modern 하지만 완전 Modern하지는 않는다.
1. AlexNet
Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton, "ImageNet Classification with Deep Convolutional Neural Networks", NIPS, 2012
ILSVRC
[ ImageNet Large-Scale Visual Recognition Challenge ]
- Classification / Detection / Localization / Segmentation
- 1,000가지의 다른 카테고리
- 100만장 이상의 이미지
- 연습 세트: 456,567 이미지

성공의 이유
- Rectified Linear Unit (ReLU)를 사용했다. → 효과적인 활성함수를 사용했다.
- GPU implementation (2개 GPU 사용하는 것)
- Local response normalization, Overlapping pooling
- Data augmentation
- Dropout
ReLU 활성함수
- 선형함수의 성질을 유지한다.
- 경사하강법으로 최적화하기 쉽다.
- Good generalization → 결과론적인 성절이다.
- Overcome the vanishing gradient problem ★★★
2. VGGNet
성질
- Increasing depth with 3 x 3 convolution filters (with stride 1)
- 1 x 1 convolution for fully connted layers
- Dropout (p=0.5)
- VGG16, VGG19
왜 3 x 3 convolution을 사용하는 가?
3 x 3 을 2개 사용하는 것과 5 x 5 하나 사용하는 것과 Receptive Field 가 동일하다.
이때 파라미터 수 294,912 409,600
3. GoogLeNet
- GoogLeNet won the ILSVRC at 2014
- Inception blocks
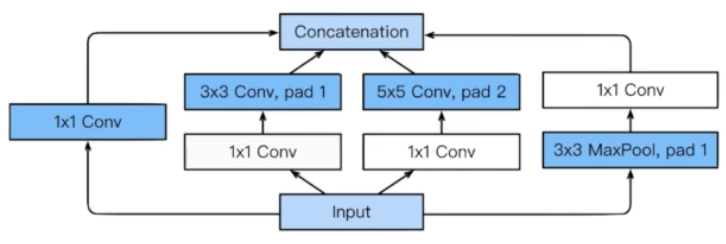
Inception Block
이점: 파라미터 수 줄어든다.
어떻게 줄이는지
1) Recall how the number of parameters is computed.
2) 1 x 1 convolution can be seen as channel-wise dimension reduction
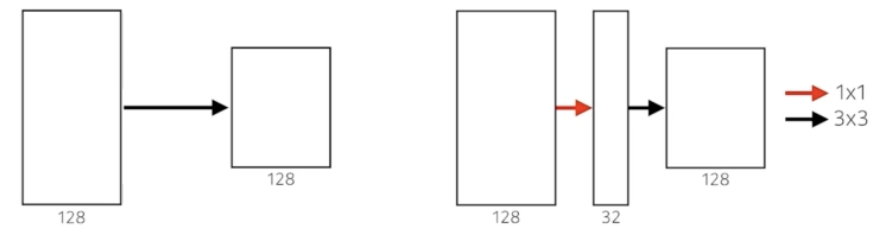
(좌)
3 x 3 x 128 x 128 = 147,456
(우)
1 x 1 x 128 x 32 = 4,096
3 x 3 x 32 x 128 = 36,864
4,096 + 36,864 = 40,960
★ 1x1 convolution enables about 30% reduce of the number of parameters!
4. Quiz
Which CNN architecture has the least number of parameters?
1) AlexNet (8-layers) → 60M
2) VGGNet (19-layers) → 110M
3) GoogLeNet (22-layers) → 4M
[답] 3번
5. ResNet
Deeper neural networks are hard to learn.
- Overfitting is usually caused by an excessive number of parameters.
- But, not in this case.
Add an identity map (skip connection)

Add an identity map after nonlinear activations:
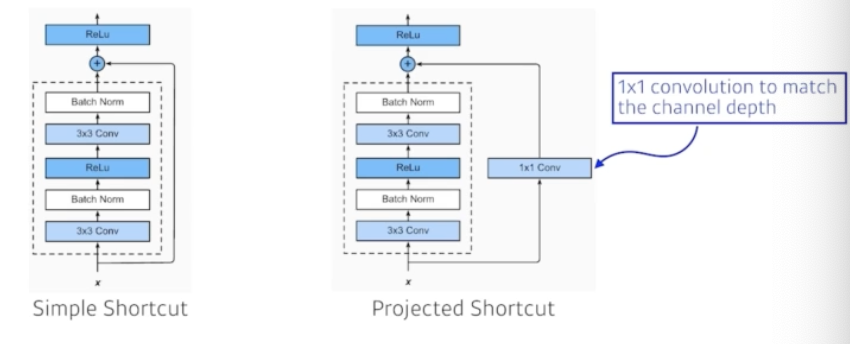
Batch normalization after convolutions:

Bottleneck architecture
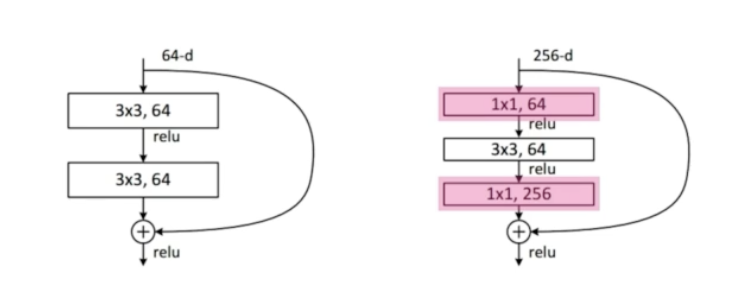
3x3 convolution 전에 input channel 줄이고, 3x3 convolution 후에 input channel을 늘리는 방식으로 적용했다.
이를 위해 3x3 convolution 앞, 뒤에 1x1 convolution을 넣었다.
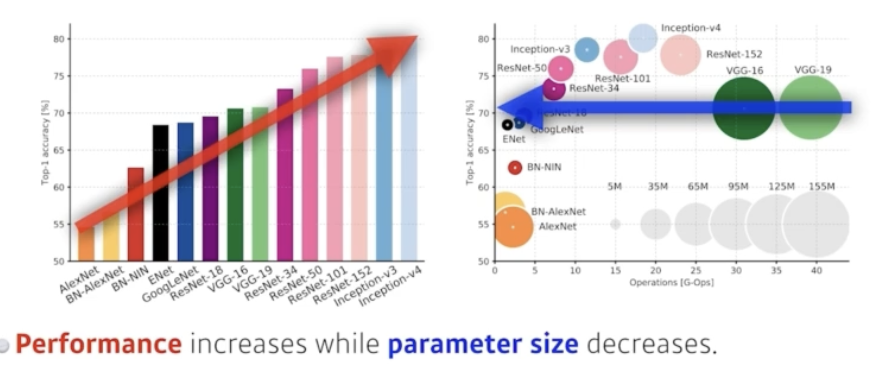
6. DenseNet
DenseNet uses concatenation instead of addition

function이 기하급수적으로 증가한다.
Dense Block
Each layer concatenates the feature maps of all preceding layers.
The number of channels increases geometrically.
Transition Block
BatchNorm -> 1 x 1 Conv → 2 x 2 AvgPooling
Dimension reduction

7. Summary
VGG: repeated 3x3 blocks
GoogLeNet: 1x1 convolution
ResNet: skip-connection
DenseNet: concatenation
©️NAVER Connect Foundation. All Rights Reserved.
'취업준비 > 인공지능' 카테고리의 다른 글
| [AI Tech] 6주차 26-2차시 Quiz 10 (2) | 2024.02.20 |
|---|---|
| [AI Tech] 6주차 26-1차시 Computer Vision Applications (2) | 2024.02.20 |
| [AI Tech] 6주차 25-1차시 CNN - Convolution은 무엇인가? (0) | 2024.02.19 |
| [AI Tech] 5주차 24차시 프로젝트 8 (2) | 2024.02.17 |
| [AI Tech] 5주차 23-4차시 프로젝트 7 (0) | 2024.02.16 |

